








Serviços Personalizados
Artigo
 Artigo em PDF
Artigo em PDF Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
Links relacionados
 Citado por SciELO
Citado por SciELO
 Similares em SciELO
Similares em SciELO
Bookmark
Revista Varianza
versão impressa ISSN 9876-6789
Revista Varianza n.11 La Paz maio 2015
ARTÍCULOS
Modelos de Regresión Binaria Bayesiana Power y Reciprocal Power Aplicación: La Calidad del Servicio de Salud Pública en la Ciudad de La Paz
Lic. Omar Chocotea Poca
omarchp@outlook.com
Resumen. En este artículo, se presenta a dos nuevos modelos de regresión binaria generales con perspectiva bayesiana, al power y al reciprocal power, e incluyen al power probit y al power logit, y al reciprocal power probit y al reciprocal power logit, respectivamente aún no disponibles en software comercial , y tienen como casos especiales al probit y al logit. El resultado de la aplicación en la data de la Encuesta Calidad de Vida en la Ciudad de La Paz en su tópico salud indica que los cuatro modelos tienen un buen performance.
Palabras clave: Modelos de regresión binaria generales; perspectiva bayesiana.
1. Introducción
Los modelos de regresión binaria son utilizados para predecir la probabilidad de una respuesta binaria (0/1) en función de diversas variables explicativas. La aplicación se encuentra en un rango más amplio de escenarios de investigación que el análisis discriminante.
Bliss (1935) introduce el primer modelo de regresión binaria, el probit, aún es utilizado, sin olvidarnos de sus contendientes históricos, el logit (Berkson, 1944) y el cloglog (Gumbel, 1958), pero el investigador no debe ser estricto con su afinidad o recomendación, más bien debe ubicar alternativas para comparar y seleccionar al mejor (Chocotea, 2014).
2. Links simétricos y asimétricos
Definición 1. Sea y = (y1 ,y2,...,yn)T un vector de n variables aleatorias independientes binarias (0/1), xi = (1 ,xi2 ,...,xik)T un vector de diseño y ![]() un vector de coeficientes de regresión. El modelo de regresión binaria, está dado por
un vector de coeficientes de regresión. El modelo de regresión binaria, está dado por
![]()
donde F(-) denota a la fda (función de distribución acumulada), su inverso F 1 () de acuerdo a la teoría del modelo lineal general es llamado link.
Un link resulta ser simétrico cuando la fda procede de una fdp (función de densidad de probabilidad) simétrica. Por supuesto, un link resulta ser asimétrico cuando la fda procede de una fdp asimétrica. También, un link asimétrico puede reducirse a un link simétrico. Chen et al. (1999), Bazán et al. (2014) y Chocotea (2014) argumentan que, cuando la probabilidad de una respuesta binaria se aproxima a 0 en una tasa diferente que cuando se aproxima a 1, los modelos con link asimétrico son adecuados.
La siguiente definición es una generalización de los resultados presentados por Bolfarine y Bazán (2010), Pewsey et al. (2012), Martínez-Flórez et al. (2013, 2014), Bazán et al. (2014), y Chocotea (2014), y es central para nuestro desarrollo.
Definición 2. Denotando por F(-) a la fda de una fdp simétrica alrededor del origen con soporte en la recta real. Sean
![]()
Los modelos definidos en (2) tienen propiedades atractivas convenientes: (a) cuando ![]() se reducen a un modelo con link simétrico; (b) la asimetría puede ser determinada por
se reducen a un modelo con link simétrico; (b) la asimetría puede ser determinada por ![]()
El modelo de regresión binaria power o reciprocal power, es caracterizado por
![]()
donde F\() denota a la fda ![]() , respectivamente.
, respectivamente.

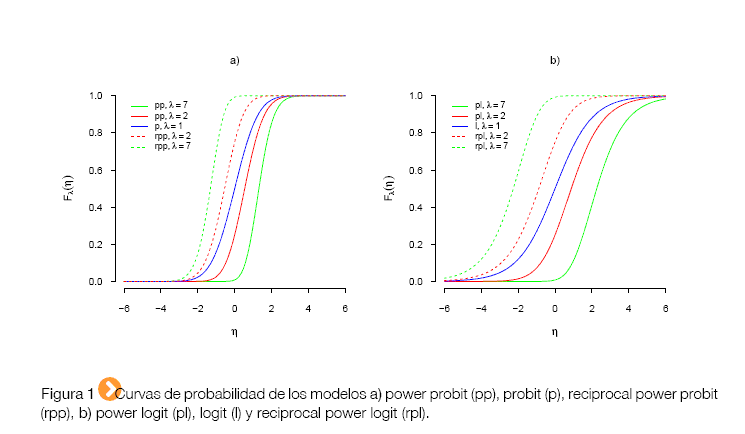
Para la estimación e inferencia, se puede utilizar la data aumentada (Bolfarine y Bazán 2010; Chocotea, 2014; Kroesey Chan, 2014). Detalles importantes de modelos de variables latentes en el análisis de datos categóricos aparecen en Agresti y Kateri (2014). Las variables latentes evitan trabajar con la verosimilitud tipo Bernoulli (Bolfarine y Bazán, 2010; Chocotea, 2014).
3. Análisis bayesiano
Asumiendo independencia entre las previas (Bazán et al., 2014), la estructura jerárquica está dada por
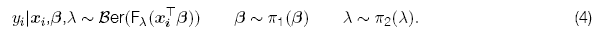
Cuando se tiene varios modelos alternativos, surge la pregunta inmediata ¿cómo los comparo y selecciono al mejor? Lo primero que no se debe olvidar es que, no siempre existe un mejor modelo, y se puede tener un conjunto de modelos que ostenten un desempeño similar. El criterio principal de bondad de ajuste para comparar modelos Bayesianos es, el Criterio de Información de la Devianza (Deviance Information Criterion: DIC). Simplificando, un modelo es mejor que otro cuando su DIC es menor.
4. Aplicación
¿Me siento satisfecho con la calidad del servicio de salud pública en general?, es una de las preguntas que se hacen miles de paceños y paceñas, pero ¿cómo podemos analizar los motivos de satisfacción o insatisfacción respecto a un amplio espectro de situaciones que condicionan su calidad de vida y su felicidad?.
El Observatorio La Paz Cómo Vamos el 2012 realizo la segunda Encuesta de Percepción Ciudadana sobre la Calidad de Vida en la ciudad de La Paz. Ilustremos el análisis a partir del tópico salud, las variables son: tiempo, e indica la insatisfacción (1) o satisfacción (0) con el tiempo de demora para conseguir una consulta médica en el servicio público; trato, e indica la insatisfacción (1) o satisfacción (0) con la calidad del trato en los centros de salud y hospitales públicos; infraequi, e indica la insatisfacción (1) o satisfacción (0) con la calidad de la infraestructura y equipamiento de los centros de salud y hospitales públicos; esfurespo, e indica la insatisfacción (1) o satisfacción (0) con el esfuerzo y responsabilidad de los paceños para cuidar la salud de la familia; y servicio, e indica la insatisfacción (1) o satisfacción (0) con la calidad del servicio de salud pública en general. Las variables explicativas serán tiempo, trato, infraequi y esfurespo, y la variable dependiente será servicio. Debido a la no respuesta en algunas preguntas, la data se reduce a 955.
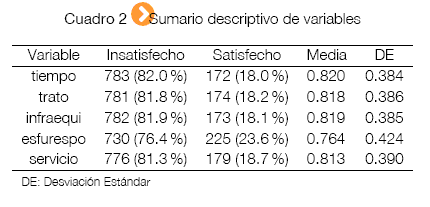
Comparemos a siete modelos de regresión binaria, al probit (M1), al logit (M2), al cloglog (M3), al power probit (M4), al reciprocal power probit (M5), al power logit (M6) y al reciprocal power logit (M7). Las fdp's a posteriori son difíciles de obtener, por lo tanto las buenas aproximaciones son dadas bajo los métodos de Monte Carlo vía Cadenas de Markov (Markov Chain Monte Carlo: MCMC). Sus sintaxis pueden ser implementadas en los softwares RStudio, R, OpenBUGS, WinBUGS, o SAS, o también online, la nueva interfaz se llama WebBUGS y solo es necesario registrarse, la dirección de la web es http://WebBUGS. psychstat.org.
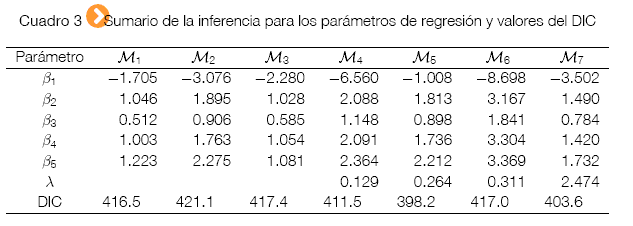
El valor del DIC determina que, el modelo con mejor desempeño o el más apropiado es el reciprocal power probit (M5).
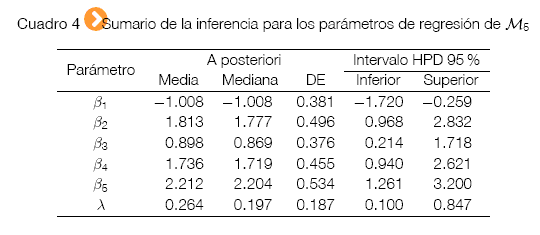
El modelo seleccionado para el análisis, está dado por
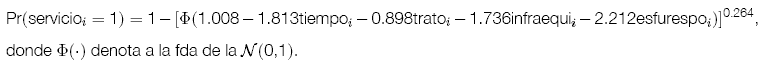
La insatisfacción con la calidad del servicio de salud pública en general se debe en primer lugar a la insatisfacción con el esfuerzo y responsabilidad de los paceños para cuidar la salud de la familia y en segundo lugar a la insatisfacción con el tiempo de demora para conseguir una consulta médica en el servicio público.
5. Conclusiones
Está claro que, la actualización del investigador va coherente con los nuevos aplicativos estadísticos para tomar mejores decisiones con los mejores modelos. Por ahora los cuatro modelos resaltaron por tener mejor desempeño.
Un estudio fortificante para una buena teoría, es el de las fdp's de las distribuciones power normal y power logística. Las extensiones van hacia los modelos de teoría de la respuesta al ítem (TRI).
Referencias
[1] Agresti, A., y Kateri, M. (2014) Some Remarkson Latent Variable Models in Categorical Data Analysis. Communications in Statistics - Theory and Methods 43, 801-814. [ Links ]
[2] Bazán, J. L., Romeo. J. S., y Rodrigues, J. (2014) Bayesian Skew-Probit Regression for Binary Response Data. Brazilian Journal of Probability and Statistics 28(4), 467-482. [ Links ]
[3] Berkson, J. (1944) Application of the Logistic Function to Bio-Assay. Journal of the American Statistical Asso-ciation 39, 357-365. [ Links ]
[4] Bliss, C. I. (1935) The Calculation of the Dosage-Mortality Curve. Annals of Applied Biology 22, 134-167. [ Links ]
[5] Bolfarine, H., y Bazán, J. L. (2010) Bayesian Estimation of the Logistic Positive Exponent IRT Model. Journal of Educational and Behavioral Statistics 35, 693-713. [ Links ]
[6] Chen, M.-H., Dey, D. K., y Shao, Q.-M. (1999) A New Skewed Link Model for Dichotomous Quantal Response Data. Journal of the American Statistical Association 94, 1172-1186. [ Links ]
[7] Chocotea, O. (2014) Modelos de Regresión Binaria Bayesiana Skew Probit. Tesis de Licenciatura, Universidad Mayor de San Andrés, La Paz. [ Links ]
[8] Gumbel, E. J. (1958) Statistics of Extremes. Columbia University Press, New York. [ Links ]
[9] Kroese, D. P., y Chan, J. C. C. (2014) Statistical Modeling and Computation. Springer, New York. [ Links ]
[10] Martínez-Flórez, G., Bolfarine, H., y Gómez, H. W. (2013) The Alpha-Power Tobit Model. Communications in Statistics - Theory and Methods 42(4), 633-643. [ Links ]
[11] ------(2014) An Alpha-Power Extension for the Birnbaum-Saunders Distribution. Statistics 48(4), 896-912. [ Links ]
[12] Pewsey, A., Gómez, H. W., y Bolfarine, H. (2012) Likelihood-Based Inferencefor Power Distributions. Test 21, 775-789. [ Links ]