








Serviços Personalizados
Artigo
 Artigo em PDF
Artigo em PDF Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
Links relacionados
 Citado por SciELO
Citado por SciELO
 Similares em SciELO
Similares em SciELO
Bookmark
Revista Varianza
versão impressa ISSN 9876-6789
Revista Varianza n.10 La Paz nov. 2013
ARTÍCULOS
Análisis Discriminante
Autor: Dr. Cs. Gustavo Ruiz Aranibar1
Resumen
La presente investigación presenta los resultados preliminares y finales de la clasificación, aplicada a la minería, teniéndose muestras analizadas, cuyos contenidos corresponden a 13 metales, teniéndose tres grupos de acuerdo al lugar de origen de cada muestra, y reagrupados hasta obtener los grupos con las muestras correspondientes.
Palabras clave: análisis discriminante, función discriminante, multivariante, distancia de Mahalanobis, variables, matriz de varianza-covarianza, centroide.
1. Introducción
El Análisis Multivariante (AM) es el conjunto de métodos estadísticos cuya finalidad es analizar simultáneamente conjuntos de datos multivariantes en el sentido de que hay varias variables medidas para cada individuo ú objeto estudiado. Su razón de ser, radica en un mejor entendimiento del fenómeno objeto de estudio, obteniendo información que con los métodos estadísticos univariantes y bivariantes no se pueden conseguir. El AM, estudia, analiza, representa e interpreta los datos que resulten de observar un número p > 1 de variables estadísticas sobre una muestra de n individuos.
2. Conocimientos previos de matemáticas y estadística
1. Matriz de datos
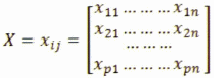
2. Suma de columnas
![]()
3. Matriz de suma de cuadrados y productos
![]()
4. Vector de promedios

5. Matriz de suma de cuadrados y suma de productos de desviaciones2
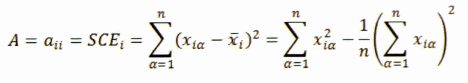
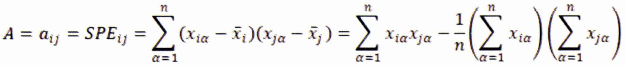
6. Covarianza
![]()
7. Matriz de varianzas y covarianzas2
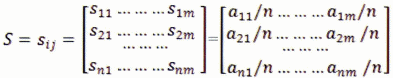
8. Vector de desviaciones estándar
![]()
9. Matriz de coeficientes de correlación
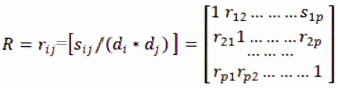
10. Matriz inversa. Existen diferentes métodos para encontrar la inversa de una matriz, estando entre ellas los métodos de: Gauss-Jordán, Monte Cario, partición de matrices, o hallando el cociente de la matriz adjunta por su determinante:![]()
11. Probabilidad total condicional
![]()
12. Fórmula de Bayes
![]()
3. Matriz de correlaciones
Cuando existen altas correlaciones entre las p variables discriminantes, el investigador debe cuidarse de interpretaciones erróneas de los coeficientes de las funciones discriminantes, porque las variables relacionadas están compartiendo el peso en la función. En investigaciones se recomienda eliminar variables altamente correlacionadas, ya que la presencia de éstas puede generar ciertas limitaciones en el análisis.
4. Descripción del análisis discriminante (AD)
El AD, fue propuesto por R. Fisher, cuya finalidad es analizar si existen diferencias significativas entre grupos de objetos respecto a un conjunto de variables medidas sobre los mismos, en el caso de que existan, explicar en qué sentido se dan y proporcionar procedimientos de clasificación sistemática de nuevas observaciones de origen desconocido en uno de los grupos analizados, es una técnica de clasificación donde el objetivo es obtener una función capaz de clasificar a un nuevo individuo a partir del conocimiento de los valores de ciertas variables discriminadoras.
El AD, permite describir, seleccionar las variables que más influyen en el problema, construir una función a partir de estas variables y predecir en qué grupo se clasifica un nuevo individuo, el cual ha sido evaluado en dicha función. Se ve a este procedimiento como un modelo de predicción de una variable respuesta categórica (variable grupo) a partir de p variables explicativas generalmente continuas (variables clasificatorias). Los pasos a seguir para llevar a cabo un AD, comprenden:
Plantear el problema a resolver por el AD.
Analizar si existen diferencias significativas entre los grupos.
Establecer el número y composición de las dimensiones de discriminación entre los grupos anal izados.
Determinar qué variables clasificadoras explican la mayor parte de las diferencias observadas.
Construir procedimientos sistemáticos de clasificación de objetos de procedencia desconocida en los grupos analizados.
Evaluar la significación estadística y práctica de los resultados obtenidos en el proceso de clasificación.
Como cualquier otra técnica estadística, la aplicación del AD ha de ir precedida de una comprobación de los supuestos asumidos por el modelo, el AD se apoya en los siguientes supuestos: a) Normalidad multivariante b) Igualdad de matrices de varianza-covarianza c) Linealidad d) Ausencia de multicolinealidad y e) Singularidad.
5. Análisis discriminante lineal (ADL)
En el AD, el punto de partida es un conjunto de objetos clasificados en dos o más grupos, de estos objetos, se conocen sus variables atributo. Al reconocer de antemano la existencia de estos grupos, parece lógico pensar que existen variables cuyo valor numérico determina la pertenencia a uno u otro grupo. Los objetivos del AD son: a) La identificación de variables atributo que mejor discriminen entre los grupos y la evaluación del poder discriminante de cada una de ellas, b) Asignar, con un cierto grado de riesgo, un objeto del que no se conoce su clasificación y del que se conocen las variables atributo.
Como técnica de análisis de dependencia, el ADL permite obtener un modelo lineal de causalidad en el cual la variable dependiente puede ser métrica o categórica, y las variables independientes son métricas, continuas y determinan a qué grupo pertenecen los objetos. Se trata de encontrar relaciones lineales entre las variables que mejor discriminen a los grupos iniciales de objetos. Además, se trata de definir una regla de decisión que asigne un nuevo objeto a uno de los grupos prefijados.
Entre las ventajas del ADL se tiene:
La técnica ADL es fácil de aplicar especialmente si se tiene el programa informático.
Las probabilidades de pertenencia a un grupo dado son determinadas por el programa.
Está disponible en muchos programas estadísticos.
Entre las desventajas del ADL se mencionan:
Las suposiciones de normalidad e igualdad de varianzas no siempre se cumplen en las variables del modelo.
La clasificación de nuevas observaciones no es muy eficiente a medida que se incrementa el número de variables del modelo.
Seleccionar las variables antes de aplicar el ADL.
Requiere que se especifiquen los grupos del conjunto de entrenamiento del modelo con clases prefijadas.
6. Análisis discriminante clásico
El AD de Fisher tiene por principio definir, para dos poblaciones y p variables, una función lineal:

Permite afectar a una de las dos poblaciones, todo individuo caracterizado por un valor negativo de y, y a la otra población todo individuo por un valor positivo de y, de todas maneras el riesgo de clasificación errónea3, (clasificación de un individuo perteneciente a una población, dentro de la otra población) sea lo más pequeña posible.
De una manera general, la investigación de la función discriminante (FD) se realiza suponiendo que las dos poblaciones poseen distribuciones normales a p dimensiones, de iguales varianzas y covarianzas, y que los parámetros de esas poblaciones son conocidas o pueden ser estimadas a partir de muestras suficientemente grandes. En estas condiciones se puede demostrar que la función asegura el riesgo de clasificación erróneo mínimo, sea:
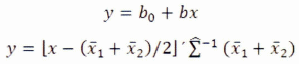
donde:
![]()
Los valores promedio de la variable y, relativos a las dos muestras son en consecuencia:
![]() y
y ![]()
La diferencia existente entre los dos promedios:
![]()
No es otro en valor absoluto, que el cuadrado de la distancia generalizada existente, en el sentido de Mahalanobis, entre las dos muestra:
![]()
Por otra parte se demuestra, siempre en las mismas condiciones, que los valores de y poseen para cada población una distribución aproximadamente normal, donde la varianza puede ser estimada por: ![]() o D2.
o D2.
Esta probabilidad es en efecto aquella de observar un valor negativo de y para un individuo de la población de promedio positivo (D2)/2 o un valor positivo de y para un individuo de la población de promedio negativo (D2)/2. En consecuencia la probabilidad de clasificación errónea puede ser calculada como sigue con la ayuda de tablas de la distribución normal reducida, donde 0 designa la función de repartición de esta distribución.
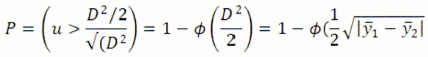
La función y, que es así definida posee una cierto número de propiedades importantes. Ella es no solamente aquella que minimiza el riesgo de clasificación errónea, pero también, en relación con la prueba T2 de Hotelling aquella que vuelve máximo la relación de la varianza de y entre las poblaciones de la varianza de y dentro las poblaciones. Dentro del espacio a p dimensiones correspondiente a las p variables observadas, la ecuación: bO + bx = 0
Es aquella de un hiperplano, donde todos los puntos son tales que las funciones de densidad de probabilidad de dos poblaciones son iguales: f1(x) = f2(x)
Este hiperplano divide el espacio a p dimensiones en dos espacios, el uno engloba todos los puntos para los cuales: f1(x) < f2(x), y el otro todos los puntos para los cuales:
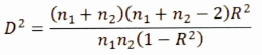
Entre el AD y la RM, existe una relación simple, entre la distancia generalizada de Mahalanobis y el coeficiente de correlación múltiple (CCM), teniéndose:
Cuando los efectos de las dos muestras son iguales:
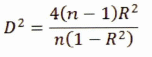
Estas relaciones permiten calcular las probabilidades de clasificación errónea a partir de los CCM.
7. Enfoque de Fisher del análisis discriminante
Encuentra una buena FD que sea una combinación lineal de las variables originales. Geométricamente: Se busca una buena dirección sobre la que se proyectará los datos de los grupos conocidos y de los que se desea clasificar. Se clasifica en función de qué grupo está más cerca en esa dirección.
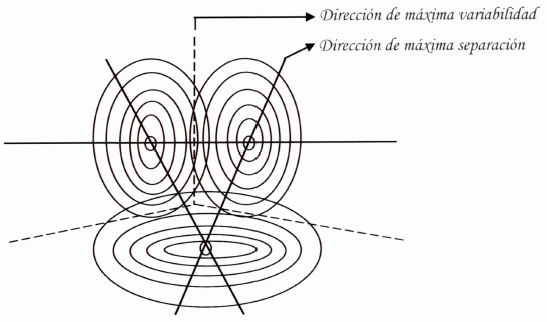
Fig. 1. Representación de las direcciones máximas considerando tres grupos
En la figura, se observa las direcciones de separación y variabilidad de las proyecciones de tres grupos de muestras, las diferentes comparaciones se realizan considerando solo dos a dos los grupos. Una buena dirección tiene que separar bien las medias y tener en cuenta la variabilidad.
8. Distancia de Mahalanobis
La distancia de Mahalanobis utiliza la inversa de la matriz, de covarianza (MC), de determinada muestra, de pertenecer a un determinado colectivo, cabe señalar que la distancia de Mahalanobis es adimensional. La distancia D2 de Mahalanobis es una medida de distancia generalizada y se basa en la distancia euclídea generalizada al cuadrado que se adecúa a varianzas desiguales; la regla de selección en este procedimiento es maximizar la distancia D2 de Mahalanobis.
Se define la distancia de Mahalanobis como: ![]()
La distancia de Mahalanobis se distribuye según una ![]() siendo p el número de variables, (
siendo p el número de variables, (![]() - dado por el investigador, n = número de variables, p = n-2).
- dado por el investigador, n = número de variables, p = n-2).
Si ![]() es < al Chi cuadrado teórico no existe observación atípica.
es < al Chi cuadrado teórico no existe observación atípica.
La distancia de Mahalanobis se usa también para calcular la probabilidad de pertenencia a cada grupo usando la regla de Bayes (para eso es necesario proporcionar una distribución a priori). En el resultado que arroja el programa informático4 del AD, se tiene la probabilidad de pertenencia al grupo asignado para cada observación.
9. Regla de Fisher con más de dos grupos
La regla de Fisher se extiende al caso en el que se desea clasificar un nuevo dato y exista tres o más grupos. Si se considera los datos utilizados por Fisher5 del año 1936, que consistió en medir los pétalos de 3 especies de flores, cada una de ellas con 4 variables, teniéndose una matriz 150x4, las tres especies son: iris setosa, iris virginiea e iris versicolor.
Utilizando el programa computacional, y observando los resultados, el clasificador ha cometido tan sólo 3 errores: dos datos de la clase versicolor han sido asignados a virginiea, y un dato de virginiea a versicolor. En la clase setosa resulta que se clasifican todas, lo que significa que pertenecen a la especie iris setosa, no así las muestras 21 y 34 de la especie iris virginiea corresponden a la especie iris versicolor y la muestra 34 de la especie iris virginiea corresponde a la especie iris versicolor.
Aplicación. La técnica del AD tiene numerosas aplicaciones, utilizándose para abordar problemas complejos en diferentes disciplinas. Una aplicación del ADL a la minería, seria considerar los datos de muestras analizadas por su composición química correspondiendo a tres grupos: área productiva, no productiva y de prospección. Cada muestra compuesta de 13 variables, que corresponde a su composición química, siendo esta información fuente para cada muestra de los tres grupos:

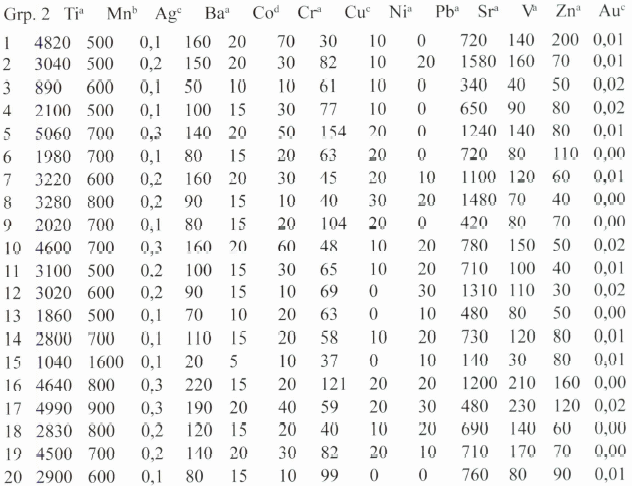

a Determinado lo más cercano a 10 ppm. c Determinado a la fracción de ppm.
b Determinado lo más cercano a 100 ppm. d Determinado lo más cercano a 5 ppm.
Resultados. Procesando esta información se observo que las muestras 9 y 15 del segundo grupo corresponden al tercer grupo, la muestra 5 del tercer grupo corresponde al segundo grupo; obteniéndose la clasificación final con los siguientes resultados:
Cuadrado generalizado de Mahalanobis = 279,88
En esta aplicación se tienen tres grupos, con 13 variables, por consiguiente se tendrán tres funciones discriminantes lineales, que son las siguientes:
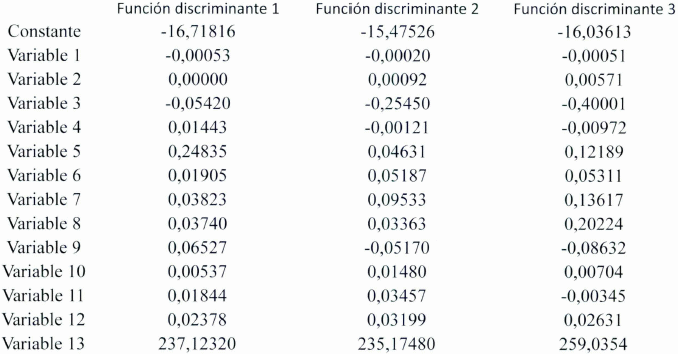
Evaluación de funciones de clasificación para cada observación

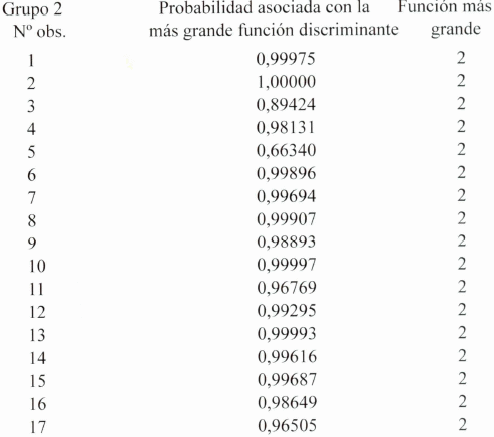

10. Conclusiones
Las muestras estarán bien clasificadas, si todas pertenecen al mismo grupo, siendo este el fin perseguido por la técnica del AD, pero puede ocurrir que en cada grupo existan muestras que pertenezcan a otros grupos, si esto acontece se debe sacar estas muestras de los grupos correspondientes, lo cual lo realiza el programa informático. Los resultados muestran la probabilidad de pertenecer al grupo correspondiente.
Colaboración
Dr. Manuel Febrero Bande. Dr. en Estadística e Investigación Operativa (1985-1990) Universidad de Santiago de Compostela - Santiago de Compostela - España
Prof. M. Nilda Aviles de Ruiz. Lie. en Idiomas. Universidad Autónoma Gabriel Rene Moreno. Santa Cruz -Bolivia (Agosto, 2005)
Notas
1 Se agradece a la UAGRM por la beca otorgada con fondos del ÍDH, para cursar y culminar exitosamente el Doctorado en Ciencias en Educación Superior. Especializado en Estadística. Profesor de Estadística, Matemáticas y Computación
2 En ingles: sums of squares and producís of desviates. En francés: sommes des carrés et des produits des écarts
2 En ingles: variance-covariance matríx, dispersión tnalrix. En francés: matricc des variances eí covariances ou matrice de dispersión
3 En ingles: misclassification. En frances: classement erroné.
4 Desarrollado por el autor de la presente investigación.
5 Multivariate Analysis, Maurice Kendal, página 40.
6 N°8O35 Calle20yAv.Ballivian,Calacoto,LaPaz-BoliviaTel.591-22772162 Cel, 67111778
gustavoru¡z432@hotma¡l.com.bo ruizaranibargustavo@gmail.com.bo Blog: Gustavo Ruiz Aranibar
Bibliografía
1. Dagnelie Pierre, analyse statistique á plusieurs variables. Les presses agronomiques de Gembloux, Bélgica, 1975 (2da. Edición), pp. 362 -Xiv. [ Links ]
2. Kendall s. Maurice, multivariate analysis. Charles Griffin & co. Ltd., Londres, Inglaterra, 1975, pp. 210 -Xi. [ Links ]
3. Davis c. John, statistics and data análisis in geology. John Wiley & Sons, New york, Estados Unidos, 1973,pp. 550-Vii. [ Links ]
4. Ruiz Aranibar Gustavo6. Libreria científica de programas informáticos, La Paz -Bolivia. [ Links ]
Pensamiento: Quien se decide a: enseñar, escribir o investigar, nunca debe dejar
de: aprender, estudiar o producir intelectualmente, para divulgar y exponer este
conocimiento