








Serviços Personalizados
Artigo
 Artigo em PDF
Artigo em PDF Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
Links relacionados
 Citado por SciELO
Citado por SciELO
 Similares em SciELO
Similares em SciELO
Bookmark
Revista Varianza
versão impressa ISSN 9876-6789
Revista Varianza n.8 La Paz nov. 2011
INVESTIGACIÓN
Análisis de Medidas Repetidas mediante Métodos de Máxima Verosimilitud
Autor: Univ. Deyvis Nina Canaviri
1 Introducción
En el análisis de experimentos con medidas repetidas ocurre con cierta frecuencia que la matriz de covarianzas no se ajusta al supuesto restrictivo de esfericidad en el análisis de varianza, o de igualdad de varianzas para cualquier par de diferencias entre tratamientos (Huyhn&Feldt, 1970). Una condición suficiente para el cumplimiento de este supuesto se da cuando las variables aleatorias están igualmente correlacionadas y tienen varianzas iguales.
Situaciones experimentales comunes provocan sin embargo que las medidas repetidas con mayor contigüidad temporal o espacial presenten correlaciones más altas. Estas situaciones generan matrices de covarianzas que incumplen el supuesto de esfericidad y pruebas F sesgadas que inflan la probabilidad de rechazar la hipótesis nula cuando es cierta por encima del criterio fijado por el investigador.
Tradicionalmente se han propuesto dos soluciones que pueden ser familiares al lector: la utilización de una prueba F con grados de libertad ajustados (Greenhouse&Geisser, 1959), y el análisis de varianza multivariado (O'Brien &Kaiser, 1985). Esta última estrategia es típicamente recomendada cuando existe una grave desviación del supuesto de esfericidad y la muestra sea grande(Jensen, 1982, 1987; Marcucci, 1986). El modelado de la matriz de covarianza mediante procedimientos de estimación de máxima verosimilitud nos lleva a una tercera estrategia que incorpora en el análisis información paramétrica más ajustada al estudio del comportamiento de interés (Wolfinger, 1993). Esta última opción ha mostrado tener más potencia estadística que la prueba F con grados de libertad ajustados en el caso de matrices de covarianza autorregresivas (Albohali, 1983; Milliken& Johnson, 1994), así como resultados favorables más parsimoniosos que el análisis multivariado de varianza (Elston&Grizzle, 1962). El objetivo de la presente comunicación es presentar dos estudios de casos que ilustren las oportunidades y problemas de esta tercera vía en el análisis de medidas repetidas, así como describir algunas características de los programas informáticos disponibles.
2 Un Caso
El estudio consiste en evaluar el efecto sobre la resistencia muscular de tres programas de entrenamiento físico (Littell, Freund&Spector, 1991). En el primero de ellos, se aumentó semana a semana el número de repeticiones de un ejercicio de levantamiento de pesas. En el segundo programa, se aumentó el peso a levantar según los sujetos ganaban en resistencia. En la tercera condición de control, los participantes no hicieron el ejercicio. Las medidas de resistencia se realizaron en días alternos durante un período de dos semanas.
El modelo lineal para un análisis de varianza univariado puede ser expresado como:

Contando en ambos casos con dos parámetros. Podemos formular las hipótesis estadísticas de efectos principales de Programa (H01), y Tiempo (H02), así como la interacción entre Programa y Tiempo (H03) del modo siguiente:
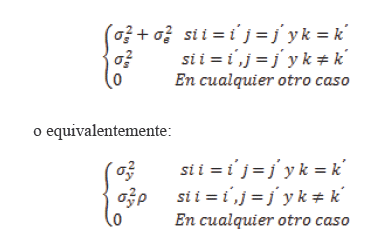
Contando en ambos casos con dos parámetros. Podemos formular las hipótesis estadísticas de efectos principales de Programa (H01), y Tiempo (H02), así como la interacción entre Programa y Tiempo (H03) del modo siguiente:

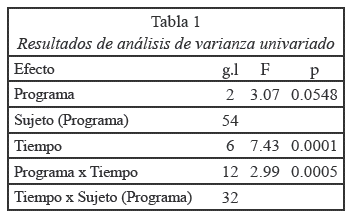
Sus resultados pueden apreciarse en la Tabla 1, resultando significativa la interacción entre programa y tiempo, pero no así el efecto principal de programa.
Un diagnóstico de la adecuación del modelo mediante el análisis de residuales revela la siguiente matriz de correlaciones, con valores decrecientes en función de la distanciatemporal entre observaciones.

La inspección visual nos sugiere un mal ajuste al criterio de esfericidad. Esto es apoyado por los resultados de la prueba de Mauchly, así como por el valor e de Geisser-Greenhouse estimado en 0.42, que se aleja del valor 1 requerido por la prueba F insesgada para los contrastes intrasujetos. A la vista del tamaño de la muestra (N = 57), y de la desviación considerable respecto de la condición de esfericidad, podemos considerar la alternativa del análisis multivariado.
El modelo lineal en este caso puede expresarse como:
![]()
en donde Y es la matriz de observaciones (Sujetos x Tiempos), X es la matriz del diseño (Sujetos x Programas),![]() es el vector de parámetros de efectos fijos o medias (Programas x Tiempos), E es la matriz de diferencias individuales (Sujetos x Tiempos) y
es el vector de parámetros de efectos fijos o medias (Programas x Tiempos), E es la matriz de diferencias individuales (Sujetos x Tiempos) y![]()
La matriz de covarianzas en este caso no tiene restricciones, por lo que cuenta con 28 parámetros distintos, 7 varianzas y 21 covarianzas.

El contraste de las hipótesis para los efectos intrasujetos equivalentes al modelo univariado ha de realizarse mediante contrastes multivariados. La hipótesis lineal general multivariada viene dada por:
![]()
en donde H es la matriz de contrastes experimentales de interés para los tratamientos entre sujetos, y M es la matriz de combinaciones lineales intrasujetos o entre tiempos de interés. Podemos expresar así las hipótesis estadísticas de efecto principal de tiempo (H02), e interacción entre tiempo y tratamiento (H03) como:
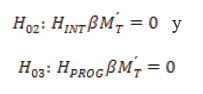
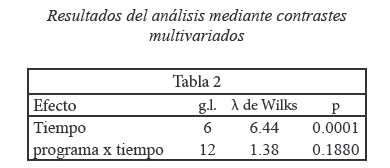
siendo Hint un vector 1 x 3 de unos, Hprog la matriz 2 x 3 de hipótesis de efecto principal de programa expresada de forma matricial, y MTla matriz 6x7 de hipótesis de efecto principal de tiempo. Estos contrastes son programados por defecto a través de los comandos de medidas repetidas en paquetes estadísticos usuales tales como Statistical Package for the Social Sciences(SPSS) o Statistical Analysis System (SAS). En los resultados en la Tabla 2 no se aprecian cambios considerables en cuanto al efecto principal de tiempo, mientras que la interacción entre programa y tiempo ha dejado de ser significativa. Una segunda alternativa al modelo univariado clásico consiste en utilizar un modelo univariado autorregresivo. Aunque podemos expresar el modelo lineal como en la ecuación (1), la diferencia radicaen la matriz de covarianzas. Esta cuenta también con dos parámetros, pero indica una correlación decreciente en función de la distancia temporal de las observaciones (d):
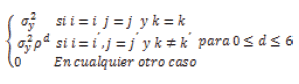
La programación en SAS del procedimiento de análisis mediante métodos de máxima verosimilitud puede consultarse en el resultado en la Tabla 3. La fundamentación teórica de los estadísticos utilizados en el contraste de estos efectos intrasujeto es expuesta en Littell, Milliken, Stroup&Wolfinger (1996).

Los métodos de máxima verosimilitud nos permiten también contrastar el ajuste de las tres matrices de covarianza utilizadas en los modelos anteriores. Como puede verse en la Tabla 4, los criterios de Akaike y Schwarz son más cercanos a cero en el caso de la matriz autorregresiva, lo que suele considerarse como un índice de mejor ajuste (Littell, Milliken, Stroup&Wolfinger, 1996). Este modelo es además más parsimonioso en cuanto que parece conseguir mejores resultados con un ahorro de 26 parámetros respecto de la matriz de covarianzas multivariada sin restricciones. Aunque todavía faltan más trabajos de investigación en este sentido, los resultados citados anteriormente (Elston&Grizzle, 1962; Albohali, 1986) apuntan al valor de una precisa especificación de la matriz de covarianzas y por lo tanto favorecerían también al último modelo.
Medidas de ajuste de las matrices de covarianza
utilizadas en los modelos univariados, multivariados y
autorregresivo

Una deficiencia de la metodología tradicional del análisis de varianza en la investigación longitudinal es que no modela explícitamente las diferencias individuales en patrones de crecimiento, relegándolas al término de error. Asume también la existencia de un diseño completo con el mismo número de observaciones por persona y espaciamiento temporal, considerando al factor de medidas repetidas como cruzado al factor sujeto. Cuando existen datos faltantes puede ocurrir que algunas razones F en el modelo univariado no tengan distribuciones exactas, y sólo sean aproximaciones que empeoran conforme aumenta el número de valores perdidos (Milliken& Johnson, 1994).
En el análisis de varianza multivariado, los paquetes estadísticos comunestales comoSASoSPSS eliminan cualquier registro incompleto antes de ejecutar los algoritmos de cálculo. Los procedimientos de máxima verosimilitud se presentan como alternativas en este sentido cuando existen muestras
grandes. Permiten además considerar las medidas repetidas como anidadas al factor sujeto, con un número desigual de observaciones por persona y distinto espaciamiento temporal. Incorporan también parámetros de variabilidad interindividual en crecimiento, cuya estimación tiene en cuenta las diferentes precisiones derivadas del distinto número de medidas hechas en cada participante.
3 Bibliografía
[1] Searle, S. R., Casella, G. &McCulloch, C. W. (1992). Variance compo -nents. New York: John Wiley. [ Links ]
[2] Smith, D. W. & Murray, L. W. (1984). An alternative to Eisenhart's modelII and mixed model in the case of ne gative variance estimates. Journalof the American StatisticalAssociation, 79, 145-151. [ Links ]
[3] Wolfinger, R. (1993). Covariance structure selection in general mixed models. Communications in statistics: Simulation, 22 (4), 1.079-1.1 0 6. [ Links ]