








Serviços Personalizados
Artigo
 Artigo em PDF
Artigo em PDF Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
Links relacionados
 Citado por SciELO
Citado por SciELO
 Similares em SciELO
Similares em SciELO
Bookmark
Revista Varianza
versão impressa ISSN 9876-6789
Revista Varianza n.8 La Paz nov. 2011
INVESTIGACIÓN
Regresión Logística
Autor: Lic. Verónica Cuenca Ramallo
Un método conocido en un modelo de regresión es la regresión logística, este método esta destinado a utilizarlo cuando se presente datos binomiales (dicotómicas) o multinomiales (multivariadas, politomicas).
En la actualidad existe muchos estudios sobre lo que es la regresión logística y sus aplicaciones en diferente áreas, en este articulo se encargara esta regresión.
1. Introducción
En estadística, la regresión logística es un modelo de regresión para variables dependientes, es útil para modelar la probabilidad de un evento ocurriendo como función de otros factores. Es un modelo lineal generalizado que usa como función de enlace la función logit.
La regresión logística es usada extensamente en las ciencias médicas, sociales y otros, esto significa áreas del conocimiento humano donde las variables que se analizan son en su mayoría cualitativas.
Otros nombres para la regresión logística usados en varias áreas de aplicación incluyen:
1.1 Modelo logístico, modelo logit, y clasificador de máxima entropía.
En los modelos de regresión se quiere conocer la relación entre:
![]() Una variable dependiente cualitativa, dicotómica (regresión logística binaria o binomial) o con más de dos valores (regresión logística multinomial).
Una variable dependiente cualitativa, dicotómica (regresión logística binaria o binomial) o con más de dos valores (regresión logística multinomial).
![]() Una o más variables explicativas independientes, o covariables, ya sean cualitativas o cuantitativas.
Una o más variables explicativas independientes, o covariables, ya sean cualitativas o cuantitativas.
Siendo la ecuación inicial del modelo de tipo exponencial, si bien su transformación logarítmica (logit) permite su uso como una función lineal.
Como vemos, las covariables pueden ser cuantitativas 0 cualitativas. Las covariables cualitativas deben ser dicotómicas, tomando valores 0 para su ausencia y 1 para su presencia (esta codificación es importante, ya que cualquier otra codificación provocaría modificaciones en la interpretación del modelo).
Pero si la covariable cualitativa tuviera más de dos categorías, para su inclusión en el modelo deberíamos realizar una transformación de la misma en varias covariables cualitativas dicotómicas ficticias o de diseño (las llamadas variables dummy), de forma que una de las categorías se tomaría como categoría de referencia. Con ello cada categoría entraría en el modelo de forma individual.
En general, si la covariable cualitativa posee n categorías, habrá que realizar n-1 covariables ficticias.
En resumen el modelo de regresión logística se utiliza cuando estamos interesados en pronosticar la probabilidad de que ocurra o no un suceso determinado.
Por ejemplo, a la vista de un conjunto de pruebas médicas, que una persona tenga una determinada enfermedad, o bien que un cliente devuelva un crédito bancario, el comportamiento electoral, color de ojos etc.
2. El modelo de la regresión logística
El modelo de regresión en el caso multivariante se considera una agrupación de p variables independientes cual esta denotado a voluntad por elvector x=(x1,x2,........,xk).
Se asume que cada uno de estas variables es una escala mínima de intervalo, permite la probabilidad condicional que la respuesta se presenta con la notación siguiente:
![]()
El modelo de regresión logística (logit) múltiple esta dada por la siguiente ecuación.

Donde los números de ensayos Bernoulli![]() son conocidos y las probabilidades de éxito
son conocidos y las probabilidades de éxito![]() son desconocidas.
son desconocidas.
El modelo es entonces obtenido en base a lo que cada ensayo (valor de![]() y el conjunto de variables explicativas/independientes puedan informar acerca de la probabilidad final. Estas variables explicativas pueden pensarse como un vector
y el conjunto de variables explicativas/independientes puedan informar acerca de la probabilidad final. Estas variables explicativas pueden pensarse como un vector![]() dimensional y el modelo toma entonces la forma
dimensional y el modelo toma entonces la forma
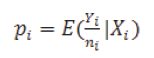
Los logits de las probabilidades binomiales desconocidas es decir los logaritmos de los odds o ratios de probabilidad que indica cuanto se modifican las probabilidades por unidad de cambio en las variables x, son modeladas como una función lineal de los![]()
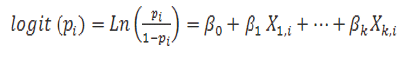
Es importante notar que el elemento particular![]() puede ser ajustado a 1 para todo
puede ser ajustado a 1 para todo![]() obteniéndose un intercepto en el modelo. Los parámetros desconocidos
obteniéndose un intercepto en el modelo. Los parámetros desconocidos![]() son usualmente estimados a través de máximo verosimilitud.
son usualmente estimados a través de máximo verosimilitud.
La interpretación de los estimados del parámetro![]() es como los efectos aditivos en el log odds ratio para una unidad de cambio en la j-ésima variable explicativa.
es como los efectos aditivos en el log odds ratio para una unidad de cambio en la j-ésima variable explicativa.
En el caso de una variable explicativa dicotómica, por ejemplo género,![]() es la estimación del odds ratio de tener el resultado para, poder decir algo, hombres comparados con mujeres.
es la estimación del odds ratio de tener el resultado para, poder decir algo, hombres comparados con mujeres.
El modelo tiene una formulación equivalente dada por:
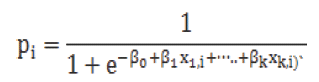
Esta forma funcional es comúnmente identificada como una red neuronal de una sola capa, calcula una salida continua en lugar de una función por partes. La derivada de![]() con respecto a x = x1...xk es calculada de la forma general:
con respecto a x = x1...xk es calculada de la forma general:
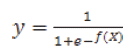
3. Algunos aspectos a tener en cuenta para el uso de la regresión logística.
Tamaño de la muestra y número de variables independientes.
4. Algunas observaciones de tipo práctico
![]() Para una mejor interpretación de los coeficientes cualesquiera
Para una mejor interpretación de los coeficientes cualesquiera![]() es necesario referirnos al concepto riesgo relativo.
es necesario referirnos al concepto riesgo relativo.
![]() El exponencial de los
El exponencial de los![]() se corresponde con el riesgo relativo, o sea, es una medida de la influencia de la variable
se corresponde con el riesgo relativo, o sea, es una medida de la influencia de la variable![]() sobre el riesgo de que ocurra ese hecho y suponiendo que el resto de las variables del modelo permanezcan constantes.
sobre el riesgo de que ocurra ese hecho y suponiendo que el resto de las variables del modelo permanezcan constantes.
![]() Una vez estimados los valores de
Una vez estimados los valores de![]() podemos determinar la probabilidad del suceso para distintos valores de los
podemos determinar la probabilidad del suceso para distintos valores de los![]()
![]() Para las variables explicativas (categóricas) ya sean nominales u ordinales de más de 2 categorías (politómicas), para incluirlas en el modelo hay que darles un tratamiento especial.
Para las variables explicativas (categóricas) ya sean nominales u ordinales de más de 2 categorías (politómicas), para incluirlas en el modelo hay que darles un tratamiento especial.
![]() Si estamos en presencia de una variable nominal con C categorías, debemos incluirla en el modelo de regresión logística como variable categórica, de manera que a partir de ella se crean C-1 variables dicotómicas llamadas dummy se debe precisar con cuál de las categorías de la variable original interesa comparar el resto y esa será la llamada categoría de referencia.
Si estamos en presencia de una variable nominal con C categorías, debemos incluirla en el modelo de regresión logística como variable categórica, de manera que a partir de ella se crean C-1 variables dicotómicas llamadas dummy se debe precisar con cuál de las categorías de la variable original interesa comparar el resto y esa será la llamada categoría de referencia.
![]() En el caso de las variables ordinales se puede asumir que la escala funciona aproximadamente a un nivel cuantitativo, se pueden manejarse como variables dummy.
En el caso de las variables ordinales se puede asumir que la escala funciona aproximadamente a un nivel cuantitativo, se pueden manejarse como variables dummy.
NOTA
El ejemplo aplicativo se realizará en la siguiente revista N° 9 se tratará para casos dicotómicos y casos multivariados, también se explicará la terminología.
5. Bibliografía.
[1] David W.Hosmer (1989) "APPLIED LOGISTIC REGRESSION " [ Links ]
[2] David W.Hosmer (2000) "LOGISTIC REGRES SION" [ Links ]