








Servicios Personalizados
Articulo
 Articulo en PDF
Articulo en PDF Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
Links relacionados
 Citado por SciELO
Citado por SciELO
 Similares en SciELO
Similares en SciELO
Bookmark
Revista Varianza
versión impresa ISSN 9876-6789
Revista Varianza n.1 La Paz oct. 2001
PROYECTOS
Técnicas bayesianas
Juan Carlos Flores López y Marisol Paredes
Elementos de Teoría Bayesiana
Se asume las observaciones ![]() sido generados de una distribución de probabilidad
sido generados de una distribución de probabilidad ![]() , tal que el parámetro
, tal que el parámetro ![]() es desconocido y la función
es desconocido y la función ![]() es conocida. Este modelo es representado por
es conocida. Este modelo es representado por ![]() , donde
, donde ![]() puede ser un vector, lo mismo que
puede ser un vector, lo mismo que ![]() .
.
Distribución a priori
Consideremos un problema de inferencia estadística en el que se van a seleccionar observaciones de una distribución cuya función de probabilidad es ![]() , donde
, donde ![]() es un parámetro de valor desconocido. Se supone que el valor desconocido del parámetro
es un parámetro de valor desconocido. Se supone que el valor desconocido del parámetro ![]() debe pertenecer a un espacio paramétrico
debe pertenecer a un espacio paramétrico ![]() . Lo que se pretende es el de intentar determinar donde es probable que se encuentre el verdadero de
. Lo que se pretende es el de intentar determinar donde es probable que se encuentre el verdadero de ![]() en el espacio paramétrico
en el espacio paramétrico ![]() , partiendo de las observaciones de la densidad
, partiendo de las observaciones de la densidad ![]() . E Esta distribución se denomina distribución a priori de
. E Esta distribución se denomina distribución a priori de ![]() , que se denota por
, que se denota por ![]()
Distribución posteriori
Supongamos que ![]() constituyen una muestra, donde los
constituyen una muestra, donde los ![]() son independientes e idénticamente distribuidas (i.i.d.), de una distribución cuya densidad es
son independientes e idénticamente distribuidas (i.i.d.), de una distribución cuya densidad es ![]() . Luego:
. Luego:
![]()
Cuando la función de densidad conjunta ![]() de las observaciones, donde los
de las observaciones, donde los ![]() son i.i.d, se considera con una función de
son i.i.d, se considera con una función de ![]() , para valores dados de
, para valores dados de ![]() ,se llama de verosimilitud y la demostraremos por
,se llama de verosimilitud y la demostraremos por ![]() . Asumimos, en resumen, para la distribución muestral
. Asumimos, en resumen, para la distribución muestral ![]() , una distribución inicial en
, una distribución inicial en ![]() y que
y que ![]() esta disponible. Dado lo anterior, podemos construir diferentes distribuciones, llamadas:
esta disponible. Dado lo anterior, podemos construir diferentes distribuciones, llamadas:
(a) la distribución conjunta de ![]()
(b) la distribución marginal de x, también llamada la distribución predictiva

(c) la distribución posterior de ![]() , obtenida por la formula de Bayes
, obtenida por la formula de Bayes

notemos que ![]() es proporcional a la distribución de
es proporcional a la distribución de ![]() condicional en
condicional en ![]() , es decir la función de verosimilitud, multiplicada por la distribución a priori de
, es decir la función de verosimilitud, multiplicada por la distribución a priori de ![]() , ya que el denominador de m(x) no depende de
, ya que el denominador de m(x) no depende de ![]() , puede ser considerado como una constante, así tenemos:
, puede ser considerado como una constante, así tenemos:
![]()
esta simple expresión encierra el núcleo de la inferencia Bayesiana.
Principio de in varianza de Jeffreys
Esta introducción introducida por Jeffreys, esta basada en considerar transformaciones uno a uno del parámetro ![]() , es decir una función del parámetro
, es decir una función del parámetro ![]() llamada
llamada ![]() . Si realizamos transformaciones de variables, la densidad a priori 7T(0)es equivalente, en términos de expresar la misma confianza, a la siguiente densidad a priori en
. Si realizamos transformaciones de variables, la densidad a priori 7T(0)es equivalente, en términos de expresar la misma confianza, a la siguiente densidad a priori en ![]() :
:
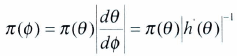
Definición.- Una familia F de distribuciones de probabilidad en 0 se dice que es conjugada (o cerrada bajo muestreo)si, para cada ![]() , la distribución posteriori
, la distribución posteriori ![]() también pertenece a F .
también pertenece a F .
Modelo normal con varianza conocida
Dada la importancia de la distribución normal en el desarrollo de la inferencia, es necesario mostrar desde el punto de vista bayesiano. Dado ![]() una muestra, (i.i.d.)de una distribución normal con media
una muestra, (i.i.d.)de una distribución normal con media ![]() desconocida, pero con varianza
desconocida, pero con varianza ![]() conocida, la distribución conjugada de
conocida, la distribución conjugada de ![]() es la distribución normal. Luego sea
es la distribución normal. Luego sea ![]() donde
donde ![]() están dados. Luego la distribución posterior también es normal, y tiene como media y varianza
están dados. Luego la distribución posterior también es normal, y tiene como media y varianza
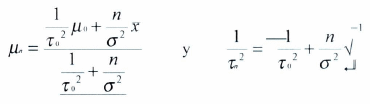
por otro lado la distribución normal multivariante esta dado por
![]()
y la función de verosimilitud para una muestra de n observaciones i.i.d. de ![]() , es:
, es:
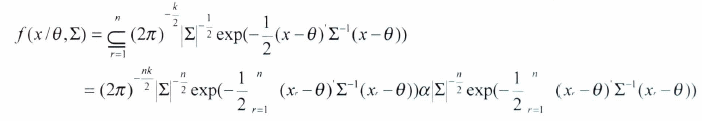
como ![]() es un escalar, tomando la traza y por propiedad de esta ultima, lo anterior se convierte en:
es un escalar, tomando la traza y por propiedad de esta ultima, lo anterior se convierte en:
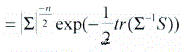
donde Skxk es la matriz de "suma de cuadrados" relativo a d.
![]()
Definición.- un modelo jerárquico de Bayes es un modelo estocástico Bayesiano ![]() , donde la distribución a priori
, donde la distribución a priori ![]() esta descompuesta en distribuciones condicionales:
esta descompuesta en distribuciones condicionales:
![]()
y una distribución marginal ![]() tal que:
tal que:
![]()
los parámetros ![]() son llamados hiperparametros de nivel i.
son llamados hiperparametros de nivel i.