








Servicios Personalizados
Articulo
 Articulo en PDF
Articulo en PDF Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
Links relacionados
 Citado por SciELO
Citado por SciELO
 Similares en SciELO
Similares en SciELO
Bookmark
Revista del Postgrado en Informática
versión impresa ISSN 3333-7777
Revista PGI n.1 La Paz nov. 2014
ARTICULO ORIGINAL
Algoritmo de Clasificación de Huellas Dactilares Basado en Redes Neuronales Función Base Radial
Victor Sarzuri Flores
Postgrado en Informática Universidad Mayor de San Andrés - UMSA La Paz, Bolivia
victor.sarzuri@gmail.com
ResumenUn sistema de identificación biométrico reconoce a un individuo por la búsqueda completa en una base de datos de modelos biométricos, esto lleva a una comparación 1 a N. En sistemas en línea, el tiempo de respuesta puede ser grande por la cantidad de comparaciones. Un algoritmo de clasificación puede ser crucial para mejorar el rendimiento de tales sistemas, de modo que permita particionar la base de datos en clases y el número de comparaciones se reduciría. El presente artículo plantea un algoritmo de clasificación de huellas dactilares basado en una red neuronal Función Base Radial optimizada por enjambre de partículas
Palabras clavebiometría; huella dactilar; clasificación; redes neuronales artificiales; función base radial; optimización por enjambre de partículas.
I. INTRODUCIÓN
A partir de la última década, los sistemas biométricos basados en huella dactilar se han vuelto comunes en nuestro medio, por su bajo costo y accesibilidad. Un sistema biométrico es esencialmente un sistema de reconocimiento de patrones, que identifica una persona determinando la autenticidad de una específica característica fisiológica y/o de comportamiento de la persona
Dependiendo del contexto de aplicación, un sistema biométrico puede ser llamado un sistema de verificación o un sistema de identificación. Un sistema de verificación autentifica la identidad de una persona por la comparación de una característica capturada con su propio modelo biométrico previamente almacenado en el sistema. Un modelo biométrico es un modelo matemático de la característica fisiológica y/o de comportamiento de la persona, esto lleva a una comparación 1 a 1 para determinar si la identidad solicitada del individuo es cierta. Un sistema de identificación reconoce a un individuo por la búsqueda en una base de datos completa de modelos biométricos. Esto lleva a una comparación 1 a N para establecer la identidad del individuo.
En aplicaciones como un Patrón Biométrico Electoral basado en huella dactilar, el proceso de identificación como es la depuración de votantes inscritos, requiere un tiempo de respuesta grande por la cantidad de comparaciones realizadas, este tiempo de respuesta no es factor importante porque el proceso es fuera de línea. Sin embargo en aplicaciones en línea como un Sistema de Pagos o un Sistema de Acceso, el tiempo de respuesta es crucial.
Este tiempo podría reducirse si se disminuye el número de comparaciones. Algunas veces, se tiene disponible información acerca del género, edad, raza u otra información individual de la persona que permiten reducir esta búsqueda, sin embargo, esta información no está disponible en muchas aplicaciones, por ejemplo en un Sistema Policial de Identificación Criminal.
Una estrategia común es dividir la base de datos en bloques basados en clases predefinidas de modo que una huella dactilar se compare en un determinado bloque basado en su clase, esto reduce el número de comparaciones en el proceso de identificación.
El presente artículo se propone el diseño de un modelo de red neuronal Función Base Radial basado en la optimización por enjambre de partículas para la clasificación automática de huellas dactilares utilizando el esquema de clasificación Galton-Henry. Este sistema clasifica las imágenes de las huellas dactilares en cinco clases: Arco, Tendiendo Arco, Curveado Izquierdo, Curveado Derecho y Espiral. Este modelo pretende establecer una mejor precisión en la clasificación y reducir el tiempo de comparación de una huella en una base de datos masiva, permitiendo mejorar el rendimiento de un sistema de identificación.
II. PLANTEAMIENTO DEL PROBLEMA
La identificación de una persona requiere una comparación de su huella dactilar con todas las huellas almacenadas en una base datos. Esta base de datos puede ser muy grande en muchas aplicaciones civiles y forenses. En tales casos, la identificación típicamente puede tener un tiempo de respuesta inaceptable. La identificación puede mejorar reduciendo el número de comparaciones. En algunos casos se tiene información acerca de la persona que puede ser utilizado para reducir la búsqueda; sin embargo, esta información no siempre es accesible. En tales casos, se puede obtener información intrínseca de la huella dactilar para una eficiente búsqueda, particionado la base de datos en clases [10].
La clasificación de huellas dactilares se refiere al problema de asignar una imagen de huella a una clase en una forma consistente y confiable.
La clasificación automática de huellas dactilares es una estrategia para reducir el tiempo de respuesta de un sistema de identificación. Este proceso tiene como fundamento las características globales de la imagen de la huella a diferencia de la comparación de huellas que se fundamenta en características locales llamadas minucias. Sin embargo debido a la calidad de la huella que puede contener ruido en la imagen este proceso es difícil y complejo.
Se considera a la clasificación automática de huellas un problema difícil de reconocimiento de patrones [2]. Debido a que existe una pequeña variabilidad entre las clases, es decir muchas huellas tienen similitud en las características globales pero su clasificación es distinta. Y hay una distribución no uniforme en cada clase, huellas que son distintas en las características globales pero pertenecen a una misma clase.
El Instituto Nacional de Estándares y Tecnología NIST publicó dos bases de datos de huellas dactilares adecuadas para el desarrollo y prueba de sistemas de clasificación de huellas dactilares: Base de Datos Especial NIST 4 [8] y Base de Datos Especial NIST 14 [9], comúnmente nombradas NIST DB4 y NIST DB14. Ambas base de datos consiste en imágenes de 8-bit con escala de grises de huellas rodadas escaneadas de tarjetas; dos diferentes instancias de huellas. Cada huella ha sido manualmente analizada por un experto y asignada a uno de las cinco clases: arco (A), curveado izquierdo (L), curveado derecho (R), tendiendo a arco (T) y espiral (W). Actualmente, en la base de datos DB4, algunas huellas ambiguas (cerca del 17%) tienen una adicional referencia a una clase "secundaria". La base DB4 tiene 2000 pares de huellas, uniformemente distribuida en cinco clases.
III. HIPÓTESIS Y OBJETIVO GENERAL
La hipótesis de presente trabajo de investigación está formulada en la siguiente pregunta: ¿La clasificación de huellas dactilares utilizando un modelo de Red Neuronal Función Base Radial basado en la optimización de enjambre de partículas, mejora el rendimiento de un clasificador automático en un sistema de identificación, obteniendo una precisión de 90% a 95% usando como referencia la base de datos NIST DB4 con un nivel de calidad de imagen tolerable?
Por lo tanto, el objetivo principal es diseñar y desarrollar un modelo de clasificación de huella dactilar basado en una red neuronal Función Base Radial optimizada por enjambre de partículas, para mejorar el rendimiento y la precisión de un sistema automatizado de identificación con huella dactilar.
IV. MARCO TEORICO
Reconocimiento Personal
La tarea fundamental en la administración de la identidad es la asociación entre un individuo y su identidad personal. Una persona puede ser reconocida basado en los siguientes
tres métodos [3]: a) lo que conoce o recuerda, b) lo que posee, y c) lo que es. Mientras que el primer método confía en el conocimiento exclusivo de alguna información secreta, como por ejemplo una contraseña, un número de identificación personal. El segundo método asume que la persona tiene la posesión exclusiva de una extrínseca marca, como por ejemplo una tarjeta de identificación, una licencia de conducir, una llave física, o un dispositivo personal como un teléfono móvil. El tercer método establece la identidad de una persona basada en su inherente característica física o de comportamiento y es conocido como reconocimiento biométrico [3].
Biometría
Biometría es la ciencia que establece la identidad de un individuo basada en atributos físicos, químicos o de comportamiento de la persona [1]. La importancia de la biometría en nuestra sociedad ha sido reforzada por la necesidad de sistemas de gestión de identidad cuya funcionalidad confía en la precisión para la determinación de la identidad individual en el contexto de distintas aplicaciones. Por ejemplo compartir recursos en una red, otorgación de acceso a facilidades individuales, realizar transacciones financieras remotas. La proliferación de servicios basados en web y el despliegue de centros de servicios al cliente descentralizado tiene la importante necesidad de sistemas fidedignos para manejar la identidad que pueda ajustarse a un gran número de individuos. La identidad de un individuo puede ser vista como la información asociada a una persona en un particular sistema de identificación. Por ejemplo, una tarjeta de crédito bancario típicamente asocia a un cliente con su nombre, contraseña, número de seguro social, dirección y fecha de nacimiento. Así, la identidad de un cliente en esta aplicación puede ser definida por esos atributos personales.
Huella Dactilar como Biometría
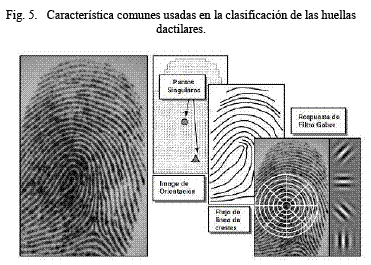
Una impresión de una huella dactilar es la reproducción de la apariencia exterior de la epidermis de la yema de los dedos. La más evidente estructural característica de una huella dactilar es un patrón intercalado de crestas y valles. En una imagen de una impresión dactilar las partes oscuras son las crestas y las partes claras son los valles [2]. El detalle de las crestas son generalmente descritas en un orden de jerarquía en tres distintos niveles: patrón global del flujo de crestas, puntos minucias, formas locales de crestas, como se muestra en la Fig.1.

A partir de las características de la imagen de una huella dactilar se construye un modelo matemático o plantilla para la comparación. En un proceso llamado registro, se obtiene un modelo de referencia que luego es almacenado en una base de datos biométrica.
Verificación e Identificación
Una importante cuestión en el diseño de un sistema biométrico es determinar como un individuo es reconocido. Dependiendo del contexto, un sistema biométrico puede ser llamado sistema de verificación o sistema de identificación.
Un sistema de verificación autentifica la identidad de una persona por la comparación de la característica biométrica capturada con una referencia biométrica previamente capturada en el proceso llamado de registro y almacenada en el sistema, esto conduce a una comparación uno a uno. Un sistema de verificación rechaza o acepta la identidad demandada.
Un sistema de identificación reconoce una persona por la búsqueda completa en una base de datos de plantillas. Esto conduce a una comparación uno a muchos para establecer si el individuo está presente o no en la base de datos y si es así retorna el identificador de referencia de registro. En un sistema de identificación, el sistema establece una identidad de la persona sin otra información que la característica biométrica.
Clasificación Automática de Huellas Dactilares
La clasificación de huellas dactilares es un procedimiento en el cual las huellas son agrupadas en una consistente y fiable forma, tal que diferentes impresiones de una misma huella son seleccionadas en un mismo grupo [1]. Este procedimiento puede ser previo a un algoritmo de comparación de modo que una consulta obtenga un subconjunto de huellas del mismo grupo o clase una base de datos y se compare con la huella. Una base de datos puede ser particionada en clases de huellas dactilares comúnmente basadas en el esquema Galton-Henry como se observa en la Fig.2
![]()
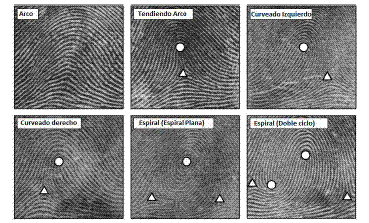
El problema de la clasificación de huellas digitales tiene un gran interés en la comunidad científica debido a su importancia e intrínseca dificultad, existe una gran cantidad de artículos que han sido publicados en los últimos años. Por lo tanto hay una amplia variedad de algoritmos de clasificación que han sido desarrollados y mejorados para este problema.
Según los autores Maltoni, Maio, Jain y Prabhakar [2], los métodos de clasificación de huellas digitales existentes pueden ser asignados de manera muy general a una de las siguientes categorías: basados en reglas, sintáctica, estructural, estadística, basado en redes neuronales y múltiples clasificadores como se observa en la Fig. 3.
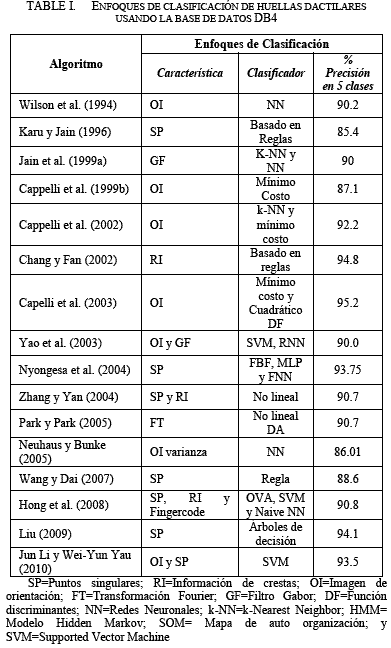
Los autores H. Li, K. Toh, L. Li [11] han realizado una recopilación importante que reflejan el progreso hecho en las técnicas automáticas de clasificación de huellas dactilares en las cuatro décadas pasadas usando como estándar la base NIST DB4, en la siguiente tabla se muestra estos enfoques.
Red Neuronal Función Base Radial basado en la Optimización de partículas
Las redes neuronales Función Base Radial han sido introducidas por Broomhead y Lowe en 1988. Este modelo de red neuronal tiene su origen en la elaboración exacta de la interpolación de un conjunto de puntos de datos en un espacio multidimensional. La red neuronal Función Base Radial es un aproximador universal, y popularmente alternativo a una red Perceptron Multicapa [4].
La red neuronal Función Base Radial que se muestra en la Fig.4 es una red de conexión hacia adelante J1-J2-J3. Cada nodo en la capa oculta usa una función base radial í>(r) como su función de activación no lineal. í>o(x) = 1 corresponde al sesgo de la capa de salida, mientras í>i(x) = í>(x-d), donde ci es el centro del i-esimo nodo y í>(x) es una función base radial. La capa oculta establece una transformación no lineal de la entrada, y la capa de salida es un combinador lineal que mapea la no linealidad en un nuevo espacio. Los sesgos de las neuronas de la capa de salida pueden ser modelados por una adicional neurona en la capa oculta, el cual tiene una función constante de activación ![]()

Para el patrón de entrada, la salida de la red es dado por:
![]() (1)
(1)
Donde ![]() es la i-esima salida de la red Función Base Radial,
es la i-esima salida de la red Función Base Radial, ![]() es el peso de conexión de la k-esima unidad oculta a la i-esima unidad de salida, ck es el prototipo o centro de la k-esima unidad oculta, y || . || denota la norma euclidiana.
es el peso de conexión de la k-esima unidad oculta a la i-esima unidad de salida, ck es el prototipo o centro de la k-esima unidad oculta, y || . || denota la norma euclidiana.![]() (.) es típicamente seleccionada como una función Gaussiana.
(.) es típicamente seleccionada como una función Gaussiana.
La optimización por enjambre de partículas PSO es una técnica de optimización desarrollada por el Dr. Eberhart y Dr. Kennedy en 1995, inspirada por el comportamiento social de las bandadas de pájaros. Este método computacional optimiza un problema por pruebas iterativas y mejora una solución candidata con respecto a una medida prestablecida de calidad. Esta es una optimización de funciones continuas no lineales que son usadas para encontrar la mejor solución en un espacio de problema.
Los trabajos más relevantes en la aplicación de esta técnica en las redes neuronales Función Base radial podemos mencionar a los autores Sharma y Mehta [5] que proponen una optimización de los nodos de la capa oculta de una red neuronal Función Base Radial. También, los autores Sun, Liu, Lin, Hsieh y Huang [6] plantean una estructura adaptativa de una red neuronal basado en esta optimización.
V. ALGORITMO PROPUESTO DE CLASIFICACIÓN DE HUELLAS DACTILARES
El algoritmo propuesto está basado en la secuencia recomendada por NIST para el procesamiento de una huella y su clasificación [7], y se describe en los siguientes pasos:
Imagen de entrada
La entrada del algoritmo es una imagen de 8-bits en escala de grises con al menos 512 pixeles de ancho y 480 pixeles de alto y escaneado en 19.69 pixeles por milímetro o 500 pixeles por pulgada como se muestra en la Fig.5

Segmentación de la imagen
El primer paso es la segmentación de la imagen huella como se observa en la Fig. 6, que produce una imagen de las dimensiones a la original cortada en una región rectangular y reduce la cantidad de datos que tiene que ser sometido en los subsecuentes procesamientos.

Mejoramiento de la imagen
El siguiente paso es mejorar la calidad de la imagen, para ello se utiliza la transformada rápida de Fourier bidimensional [6], que convierte la imagen original en una representación de frecuencias, luego se aplica una función no lineal que incrementa el dominio de información útil relativo al ruido. En la Fig. 7 se muestra una imagen mejorada.

Imagen de Orientación
Luego, se detectan en cada localización de pixel de la imagen de la huella dactilar, la orientación local de las crestas y los valles, y producir un arreglo de promedios regionales de esas orientaciones como se observa en la Fig. 8

Registración
El siguiente paso es un proceso que el clasificador utiliza para reducir la cantidad de variación de la traslación entre arreglos de orienciación similares, este es llamado registración. El algoritmo utilizado es el propuesto por Wegstein [7]. En la Fig.9 se muestra el resultado de este proceso, El signo + es el punto de registración (coro) encontrado por el algoritmo de Wegstein, y el signo + encuadrado es el punto de registración estándar.

Transformación de caracteristicas
Este paso aplica una transformación lineal al arreglo de orientación registrada. La transformación lleva a cabo dos procesos. El primero, la reducción de la dimensionalidad del vector de características. Segundo, la aplicación de un patrón fijo de pesos de regiones los cuales con grandes en la importante área central del arreglo de orientación. En la Fig.10 se muestra los valores absolutos de la región de pesos optimizado, cada cuadrado representa un peso, asociado con un bloque 2x2 del arreglo de orientación registrada.

Red Neuronal Función Base Radial
En este paso se toma como entrada un vector de características. Los pesos son el resultado de un proceso de entrenamiento, optimizado por el algoritmo de enjambre de partículas, el cual obtiene los mejores resultados con los datos de entrenamiento, la salida de la red es un conjunto de niveles de confianza para cada posible clase de salida y una indicación de cuál es la hipotética clase tiene mayor confianza.
VI. PROCESO DE ENTRENAMIENTO DE LA RED NEURONAL FUNCIÓN BASE RADIAL
Un importante paso en el entrenamiento de las redes neuronales Función Base Radial es decidir un número apropiado de nodos de la capa oculta. Si este número de nodos no es escogido apropiadamente la red neuronal puede presentar un baja capacidad de generalización global, una velocidad lenta en el entrenamiento, y requerir de un espacio grande de memoria.
La capa oculta de una red Función Base Radial actúa como un campo operativo en el espacio de datos de entrada. El número de nodos de la capa oculta se basa en la distribución del conjunto de datos del entrenamiento. Se define un factor de distancia de agrupamiento, e, el cual es la máxima distancia entre el ejemplo de entrada y un específico nodo central y permite que el número de función base incremente iterativamente acorde este factor. Por lo que decidir un conveniente factor de distancia de agrupamiento e es una condición crucial para la creación de una óptima estructura de la red neuronal. Un algoritmo de enjambre de partículas PSO permite la búsqueda un óptimo de ![]() [6].
[6].
Un enjambre de PSO consiste de un número de partículas. Cada partícula representa una potencial solución de la tarea de optimización. Todas las partículas iterativamente descubren una probable solución. Cada partícula genera una posición acorde de la nueva velocidad y la previa posición de la partícula, y este es comparado con la mejor posición el cual es generado por las previas partículas acorde al costo de una función. La mejor solución es almacenada, cada partícula acelera en la dirección de no solamente la mejor solución local, sino también de la solución global.
Si N denota el número de enjambres, en general existen tres atributos, actual posición ![]() , actual velocidad
, actual velocidad ![]() y la mejor solución anterior
y la mejor solución anterior ![]() para partículas en el espacio de búsqueda. Cada partícula en el enjambre es iterativamente actualizada acorde a los atributos mencionados, asumiendo que la función objetivo
para partículas en el espacio de búsqueda. Cada partícula en el enjambre es iterativamente actualizada acorde a los atributos mencionados, asumiendo que la función objetivo ![]() va a ser minimizada y la dimensión consiste de n partículas, entonces la nueva velocidad de cada partícula es actualizada por
va a ser minimizada y la dimensión consiste de n partículas, entonces la nueva velocidad de cada partícula es actualizada por 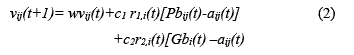
Donde vij es la velocidad de la j-esima partícula del i-esimo enjambre para todos![]() es el peso de inercia de la velocidad, c1 y c2 denota los coeficientes de aceleración, r1 y r2 son dos valores aleatorias uniformes escogidos del rango (0,1), y t es el número de generaciones. La nueva posición de la i-esima partícula es calculada como sigue:
es el peso de inercia de la velocidad, c1 y c2 denota los coeficientes de aceleración, r1 y r2 son dos valores aleatorias uniformes escogidos del rango (0,1), y t es el número de generaciones. La nueva posición de la i-esima partícula es calculada como sigue:
![]() (3)
(3)
La mejor solución anterior de cada partícula es actualizada por:
![]() (4)
(4)
La mejor solución global Gb podría ser encontrado desde todas las partículas durante los anteriores tres pasos y es definido por:
![]()
Para la búsqueda de un aceptable valor de e en el entrenamiento de una red neuronal Función Base Radial, puede utilizarse una función de la raíz de error cuadrado medio (RMSE) el cual evalúa la discrepancia entre los datos ejemplo de salida yn y la salida esperada y*n. Así, la función objetivo para Nt ejemplos es definida como (6).
![]()
Donde yn(k) es la salida esperada del k-esimo datos de ejemplo el cual es obtenido por el valor de e durante el entrenamiento.
El objetivo es minimizar el valor de ![]() . El algoritmo en pseudo código de la búsqueda por enjambre de partículas del factor de distancia de agrupamiento se muestra en la Fig.11.
. El algoritmo en pseudo código de la búsqueda por enjambre de partículas del factor de distancia de agrupamiento se muestra en la Fig.11.

VII. RENDIMIENTO DEL ALGORITMO DE CLASIFICACIÓN
El rendimiento de un algoritmo de clasificación de huellas dactilares es medido en términos de error promedio o precisión. El error promedio es calculado como el radio entre el número de huellas erróneamente clasificadas y el número total de huellas de ejemplo en el conjunto de prueba. La precisión es el porcentaje de huellas dactilares correctamente clasificadas [2].
error promedio % = número de huellas erróneamente clasificadas * 100 / número total de huellas (7)
precisión = 100% - error promedio (8)
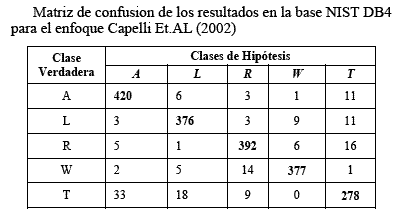
Por ejemplo, en la TablaI el enfoque de Capelli et al. (2002) muestra un porcentaje de precisión de 92.2, por lo que el error promedio es de 7.85. El valor de precisión es obtenido por la matriz de confusión [2], esta matriz tiene una fila para cada clase verdadera y una columna para cada clase de hipótesis, cada celda de una fila r y columna c reporta cuantas huellas que pertenecen la clase r es asignada a la clase c como se muestra en la tabla II, donde las clases son: arco (A), curveado izquierdo (L), curveado derecho (R), tendiendo a arco (T) y espiral (W).
Entonces los valores se calculan de la siguiente forma: Error promedio % = 157*100 / 2000 = 7.85 (9)
Precisión = 100% - 7.85 = 92.2 % (10)
VIII. CONCLUSIONES
Este artículo presenta la importancia de la clasificación de huellas dactilares en el rendimiento de un sistema de identificación, también aborda el problema de clasificación como un problema de reconocimiento de patrones complejo.
Luego se plantea un diseño inicial de un algoritmo de clasificación de huellas dactilares basado en una red neuronal Función Base Radial optimizada por enjambre de partículas. Se espera obtener un promedio del 90% al 95% de precisión en la clasificación, usando como referencia la base de datos NIST DB4.
REFERENCIAS
[8] A. K. Jain, P. Flynn, y A. Ross, “Handbook of Biometrics”, New York: Springer, pags. 1–22, 2008.
[9] D. Maltoni, D. Maio, A. Jain y S. Prabhakar,”Handbook Of Fingerprint Recognition”, 2rd ed., London: Springer 2009, pags.235–269.
[10] A. Jain, A, Ross y K. Nandakumar, “Introduction to Biometrcis”, New York: Springer, 2011, pags. 51–96.
[11] K. Du, y M. Swamy, “Neural Networks and Statistical Learning”, London: Springer-Verlag, 2014, pags. 298-335.
[12] J. Sharma, y S. Mehta, S. “Training of Radial Basis Function Using Particle Swarm Optimization”. International Journal of Engineering Research and Development, Volumen 7, Nro. 10, 2013, 10 de Julio.
[13] T. Sun, C. Liu, C. Lin, S. Hsieh, y C. Huang. “A Radial Basis Function Neural Network with Adaptive Structure via Particle Swarm Optimization”. Particle Swarm Optimization. Croacia; In-Tech 2009, pags 423-396.
[14] C. Watson et.al.,”User’s Guide to NIST Biometric Image Software (NBIS)”. National Institute of Standards and Technology (NIST),2013. Estados Unidos de America. Pags. 18-42.
[15] National Institute of Standards and technology, “NIST Special Database 4: NIST 8-Bit Gray Scale Images of Fingerprint Image Groups(FIGS)”, 2014. Disponible: http://www.nist.gov/srd/nistsd4.cfm
[16] National Institute of Standards and technology, “NIST Special Database 14: NIST Mated Fingerprint Card Pairs 2 (MFCP2)”, 2014. Disponible: http://www.nist.gov/srd/nistsd14.cfm
[17] A. K. Jain and S. Pankanti, "Fingerprint Classification and Recognition", The Image and Video Processing Handbook, A. Bovik (ed), Academic Press, 2000. Disponible: http://www.cse.msu.edu/rgroups/biometrics/Publications/Fingerprint/MSU-CPS-99-5.pdf [ Links ]
[18] H. Li, K. Toh, L. Li, “Advanced Topics in Biometrics”, World Scientific, 2011.