








Servicios Personalizados
Articulo
 Articulo en PDF
Articulo en PDF Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
Links relacionados
 Citado por SciELO
Citado por SciELO
 Similares en SciELO
Similares en SciELO
Bookmark
Revista de Investigación Estudiantil Iluminate
versión impresa ISSN 2415-2323
Rev. Inv. Est. I. v.11 n.1 La Paz nov. 2019
ARTÍCULO ORIGINAL
Clasificación de clientes con redes neuronales para prevenir abandonos a un servicio
Classification of clients with neural networks to prevent dropouts to a service
Rodrigo Alejandro Cauna Coarite1, Christian Gerardo Cruz Benítez2
1 Estudiante de ingeniería de sistemas Universidad La Salle rcaunacoarite@gmail.com Instituto de Investigaciones en Ciencia y Tecnología de la Universidad La Salle, La Paz- Bolivia
2 Estudiante de ingeniería de sistemas Universidad La Salle cruzitocris21@gmail.com Instituto de Investigaciones en Ciencia y Tecnología de la Universidad La Salle, La Paz- Bolivia
Artículo Recibido: 05-07-2019 Artículo Aceptado: 10-10 2019
Resumen
Los sistemas, formados por varios conjuntos de elementos, tienden a perder estabilidad cuando elementos se separan del sistema, para solucionarlo una red neuronal obtendrá patrones de separación con una base de datos de afiliados que están por cambiar de seguro médicoy los clasificará para anticipar su separación con el seguro. Usando metodología cuantitativa de diseño no experimental longitudinal, la red clasificará a los afiliados en base a si abandonarán o seguirán utilizando el seguro. Tras hacer pruebas, la red funcionó con un índice de aciertos de 91.43%, con otra base de datos similar el índice de aciertos fue de 90.18%. Con dichos resultados se concluyó que la red funciona efectivamente para cualquier otro servicio siempre que posea información sobre este tipo de usuarios.
Palabras Clave: Recles neuronales, separaciones, sistemas.
Abstract
The systems, formed by several sets of elements, tend to lose stability when elements are separated from the system, to solve a neural network will obtaín separation patterns with a datábase of afñliates who are about to change medical insurance and classify them to anticípate their separatíon with the insurance, Using quantitative methodologies, the network will classify afñliates based on whether they will abandon or continué to use insurance, After testing, the network worked with a hit rate of 91,43%, with another similar datábase the hit rate was 90,18%, With these results it was concluded thatthe networkworks effectively forany otherservice aslongasithas information about this type of users,
Keywords: Neural networks, separations, systems.
1. Introducción
Con el conocimiento sobre los sistemas, sobre cómo conforman el mundo en la actualidad, se llega a conocer conceptualmente como "un conjunto de partes c elementos organizadosy relacionados que interactúan entre sí para lograr un objetivo" CAIegsa, 2018, pág. 1). Por dicho concepto, se entiende lo importante quepuedeserun sistema en la actualidad, porque ninguna organización sería capaz de sostenerse sin el apoyo de sus empleados, ya que son parte de la organización cumpliendo el pape de los elementos organizados del sistema. Sin embargo, estos sistemas no siempre legan a ser permanentes y en muchos casos son inestables, porque cuando no hay algo en común entre los elementos del sistema, estos se separarán eventualmente le cual disuelve el sistema que se había formado.
Con un ejemplo para probar este punto, se tiene una base de datos de una cooperativa de salud, con varios datos sobre el comportamiento de los afiliados inscritos a la institución durante un periodo de 12 meses, estos datos son de afiliados que abandonaron el seguro médico y de afiliados que siguen utilizando el seguro médico. La base de datos cuenta con información sobre las características sociodemográficas y comportamiento en salud de los afiliados.
El problema que el seguro médico enfrenta es encontrar la manera de evitar que sus usuarios abandonen el servicio que les ofrecen con la información que tienen disponible, ya que sus clientes forman parte del sistema que creó el seguro médico pero muchas causas provocan que estos decidan abandonar el seguro, y sin ellos e seguro se quedará sin clientesy no será capaz de mantenerse.
Más allá de tratarse de un seguro médico, el problema se extiende esencialmente a todos los sistemas, porque todos ellos dependen de sus elementos para sobrevivir. Si existiera una manera de advertir una posible ruptura de los elementos con el sistema, este sería capaz de tomar una acción que evite tal ruptura.
Por esa razón, la solución propuesta para resolver el problema consiste en predecir e patrón que tienen os afiliados cuando están por abandonar el seguro médico, para que a institución pueda disuadir a los afiliados enfocándose principalmente en aquellos con la intención de abandonarel servicio del seguro médico, ofreciendo algún incentive para sus afiliados o de otra manera dependiendo de la decisión que vaya a tomar la institución con la información provista.
Para dicha solución es necesario el uso de un sistema de aprendizaje automático, debido a que tratándose de personas los patrones obtenidos no serán demasiado da ros como para que se pueda obtener una respuesta quesea completamente efectiva para resolver el problema. El sistema de aprendizaje se actualizará automáticamente utilizando la información de la base de datos, para aprenderlo mejor que pueda de ella, mostrando el grupo de afiliados que se presume abandonaran el seguro.
En la actualidad, se puede obtener el resultado que se desea casi de forma completa, clasificando a los usuarios con una red neurona que nos permita hacer minería de datos para hallar el patrón en los usuarios. Para ello, será necesario utilizar una metodología
cuantitativa con diseño no experimental, mediante la aplicación de la red neurona experimentando con los datos de entrada, de la base de datos del seguro médico. Los datos hallados, mediante el entrenamiento de la red neuronal serán analizados con el propósito de describir patrones.
2. Referentes conceptuales
a. La red neuronal
Si definimos lo que es una red neuronal sabremos que "es un paradigma de aprendizaje y procesamiento automático inspirado en el funcionamiento del sistema nervioso humano" (Calvo, Diego Calvo, 2017, pág. 1). Siendo un paradigma de aprendizaje, la red neuronal nos servirá para que podamos encontrar un patrón haciendo un aprendiza-|je supervisado, principalmente porque "la red neuronal artificial, al igual que las redes biológicas aprenden por repetición, por lo que cuantos más datos tengamos para en-trenary cuantas más veces se entrene, la red mejorara al obtener resultados más exactos". (Calvo, Diego Calvo, 2017, pág. 1). De esta manera la gran cantidad de datos, proporcionara una ventaja para que encontremos el mejor de los patrones. Sin embargo, la red requiere del ajuste correcto para que su aprendizaje sea el más preciso, por lo que resulta necesario experimentar con la red neuronal hasta que se encuentre el mejor aprendizaje.
b. Tipo de red neuronal aplicada al proyecto
Para la realización de este proyecto, se usara un tipo de red neuronal conocida comúnmente como red neuronal multicapa o Perceptron multicapa, como se menciona por Diego Calvo "es una red neuronal compuesta por una capa de neuronas de entrada y una capa de neuronas de salida, que dispone de un conjunto de capas intermedias (capas ocultas) entre la capa de entraday de salida". (Calvo, Diego Calvo, 2017, pág. 1). En estas capas ocultas se realizarán los cálculos necesarios para el aprendizaje de la máquina el cual deberá ser de tipo no supervisado.
c. Otras redes neuronales relacionadas al proyecto
Existen varios proyectos similares, aunque muchos de ellos utilizan diferentes estrategias para poder analizar patrones a pesar de poseer un objetivo similar al de este [ proyecto.
Entre los más destacables se tiene el "Proyecto del abandono Universitario: Variables explicativas y medidas de prevención", en este proyecto se hace uso de valores estadísticos a través del uso de muéstreos aleatorios de universitarios en la universidad de Oviedo con el propósito de utilizar varias técnicas de estadística para predecir e abandono de los universitarios, una de estas técnicas incluye superficialmente la aplicación de minería de datos.
Otro proyecto similar es "Aplicación de la minería de datos en la extracción de perfiles de deserción estudiantil", el cual trata de determinar la deserción escolaren Colombia a través del uso exclusivo de plataformas que permitían la aplicación de minería de datos utilizando distintas bases de datos.
El proyecto que es bastante similar al proyecto actual, es el proyecto de "Diseño de un modelo predictivo de fuga de clientes utilizando arboles de decisión", el cual, haciendo uso de árboles de decisión, calcula los abandonos de una empresa de telecomunicaciones.
A pesar de que existen proyectos con objetivos similares, no se encontró ninguno que utilizando redes neuronales busque encontrar patrones de abandono. Lo que si se encontró, fueron proyectos relacionados a calcular el rendimiento de instituciones educativas como por ejemplo en "Modelos de redes neuronales Perceptron multicapay de base radial para la predicción del rendimiento académico de alumnos universitarios" en el cual se utiliza el mismo tipo de red neurona , pero con un tipo diferente de aprendizaje automático, el cual es backpropagation o propagación hacia atrás.
3. Metodología
Para el presente estudio se aplicó una metodología cuantitativa, de diseño no experimental longitudinal. El análisis se realizó aplicando una red neuronal de tipo Perceptron.
a. Pruebas a la red neuronal
Para crear la red neuronal se utilizó "el software de desarrollo para calculo técnico" (The MathWorks Inc, 2019) Matlab. Tras haberla creado se realizaron varias pruebas cambija ndo varios de los elementos de la red, especialmente el índice de aprendizaje de la red | (que se representa con u), el índice alfa para la corrección de la red, la cantidad de neuronas o capas ne uro na les que usa la red y el método que utilizará la red para entrenar os datos. Estas pruebas se realizaron con la base de datos del seguro médico usando 400 datos para el entrenamiento de la red y 400 datos para hacer pruebas, haciende 10 Iteraciones porcada cambio que se hizo para perfeccionar el aprendizaje de la red.
b. Resultados de las pruebas
Se realizaron 12 cambios y se obtuvo la tasa de error de cada cambio para podercom-parar los resultados, estos se datos se ven en la tabla 1 con los promedios de errortras cada cambloy en el gráfico 1 se muestra los datos de la tabla 1 en forma de gráfico.
Tabla 1. Tabla de tasas de error

Fuente: Elaboración propia
Se obtuvo también una tabla 2 con la tasa de aciertos de cada cambio realizado a la red neurona a partir de la diferencia entre la cantidad de datos y el promedio de error que había, con el propósito de visualizar desde otra perspectiva los resultados obtenidos.
Tabla 2. Tabla de tasas de acierte
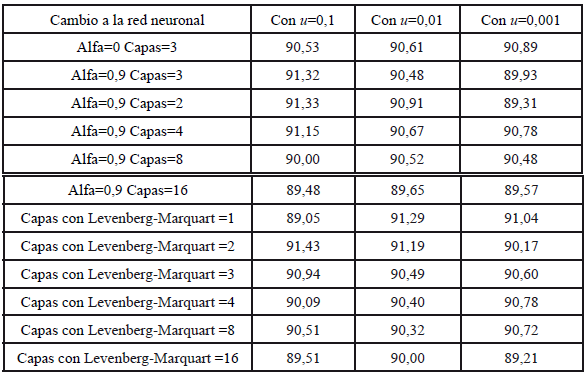
Fuente: Elaboración propia
Gráfico 1. Aciertos en las pruebas de la red neurona

Fuente: Elaboración propia
Cada uno de los puntos en las líneas que se muestran, en el gráfico 1, representa un cambio realizado durante el método de aprendizaje, donde las líneas representan e índice de corrección u, en el que se verifica que cada vez que se va aumentando la cantidad de capas, la red neuronal no presenta el mismo resultado. De esto, se destaca que hay un punto en el cual, el índice de aciertos es más alto comparado con el resto.
4. Conclusión
Los resultados revelan que el método más exitoso de aprendizaje fue el método de Levenberg-Marquart utilizando 2 capas ne uro na les y teniendo un índice de aprendizaje equivalente a 0.1, tras haber tenido un error aproximado de 8.57 siendo el mínimo error obtenido en comparación a los otros cambios realizados.
Con esta información se puede utilizar una nueva base de datos que pondrá a prueba la red neuronal, con el propósito de comprobar que la red está correctamente entrenada de manera que se pueda comparar con otros datosy se pueda hallar un patrón. Para ello, se utilizó una base de datos de la misma página de internet con diferentes datosy con las mismas características obtenidas de la primera base de datos. Si el índice de error no se aleja mucho de lo obtenido en la primera base de datos, se habrá comprobado que la red neuronal se puede aplicar a otras bases de datos.
Experimentando con la red neuronal utilizando una base de datos diferente, os resultados son diferentes.
Al probar con la otra base de datos, utilizando el método de aprendizaje de Levenberg-Marquart con 2 capas neuronalesy un índice de aprendizaje de 0.1, el índice de error que se obtuvo fue de 9.82 tras hacer 10 iteraciones con los 400 datos de aprendizaje y los 400 datos de prueba de la primera base de datos. Lo que significa que, de 400 datos estudiados, se estima un promedio de error aproximado a 10 datos.
Con estos resultados se puede apreciarque la base de datos con la que se entrenó la red neuronal pudo ser capaz de alcanzar un índice de error bastante bajo, aunque la primera base de datos con la que se trabajó presentó menos errores que con la segunda, por lo que la primera base de datos se resolvió mejor. A pesar de eso, los resultados que se obtuvieron fueron bastante cercanos entre sí, con índices de error similares entre ambos, por lo que se espera que si se pueda aplicar a otros servicios con una variación leve como la que se pudo ver en el experimento.
Con estos datos se debería poder anticipar de manera casi completamente efectiva la decisión de usuarios de un servicio que deseen abandonarlo. Entonces será decisión de la organización responsable de dicho servicio, si usaran la información para volver a atraer a sus clientes o usuarios, para que de esa manera los usuarios del servicio, desistan de la idea de retirase. De esta manera la institución que ofrece el servicio podrá mejorar sus servicios, ofreciendo beneficios, ventajasy otras estrategias, que eviten el abandono del servicio.
5. Discusión
Comprobando con el estudio más similar3, en el cual se involucraban bases de datos de distintas compañías de telefonía, utilizando el método de árboles de decisión, se pudo notar que este estudio obtuvo mejores resultados de los que se obtuvieron en el presente estudio. Los otros estudios revisados, sólo comparten el procedimiento realizado.
Referencias
Alegsa. (27 de Agosto de 2018). Definición de sistema. Obtenido de http://www.alegsa.com.ar/Dic/sistema.php [ Links ]
Asencios, V. V. (2004). Data Mining y el descubrimiento del conocimiento. Industria Data, 83-86. [ Links ]
Berza , F. (2 006). Fia naga n. Obten ido de http://flanagan.ugr.es/docencia/2005-2 006/2/apuntes/ciclovida.pdf [ Links ]
Calvo, D. (17 de Julio de 2017). Diego Calvo. Obtenido de http://www.diegocalvo.es/defin idon-de-red-neurona/ [ Links ]
Calvo, D. (13 de Julio de 2017). Diego Calvo. Obtenido de http://www.diegocalvo.es/clasificadon-de-redes-neuronales-artificiales/ [ Links ]
Gutiérrez, A. B., Menéndez, R. C, Rodríguez-Muñíz, L.J., Pérez, J. C, Herrero, E.T., & García,M. E. (2015). Predicción del abandono universitario: Variables explicativas y medidas de prevención. Revista Fuentes, 63-84. [ Links ]
Longoni, M. G, Porcel, E. A., López, M. V, & Dapozo, G. N. (2010). Modelos de Redes Neuronales Perceptrón Multicapa y de Base Radial para la predicción de rendimiento. Vil Workshop Bases de Datos y Minería de Datos (WBD) (págs.692-701). Sedicí. [ Links ]
Morales, E. F., Correa, F. M., & Valle, M. A. (2017). Diseño de un modelo predictivo de fuga de clientes utilizando árboles de decisión. Revista Ingeniería Industrial, 7-23. [ Links ]
National Science Foundation, Rexa.info. (2009). UCI Machine Learning Repository. Obtenido de https://archive.ies.uci.edu/ml/index.php [ Links ]
Pereira, R. , Romero, A. C, & Toledo, J. J. (2013). Aplicación de la minería de datos en a extracción de perfiles de deserción estudiantil. Ventana Informática, 31-47. [ Links ]
Rodrigo, M. F., Molina, J. C, Ros, R. C, & González, F. P. (2012). Efectos de interacción en a predicción del abandono en los estudios de Psicología. Anales De Psicología /Annals of Psychology, 113-119. [ Links ]
The MathWorks Inc. (2019). MathWorks. Obtenido de https://la.mathworks.com/ [ Links ]